







최소 비용으로 효율적인 GPU 사용
성능은 좋지만 높은 비용, 비용은 낮지만 부족한 성능.GPU 공유 서비스의 한계를 극복했습니다.
최대 70% 경제적으로 사용하는 GPU.비용 걱정 없이 사용한 만큼만 이용하세요.
시간당 GPU 사용 비용
- H100 X 1
- H100 X 8
- A100
- V100 X 2
- gcube
- 자사
- 타사
- 타사
- 1개월 기준
- ??만원 부터 이용할 수 있습니다.
gcube는 GPU 이용 시 사용하지 않은 시간은 비용을 부과하지 않습니다. 실시간 모니터링을 통해 실제 리소스 사용 비율에 따라 비용이 부과됩니다.

경제적이고 다양한 GPU
gcube에서 원하는 목적과 스펙의다양한 GPU를 선택할 수 있습니다.
gcube에서 원하는목적과 스펙의 다양한 GPU를선택할 수 있습니다.
- TIER 1정부 지원 사업용 대규모 데이터 처리
- 대용량
- 고사양
- 24시간 안정적
Cloud 사업자가 제공하는 GPU
- TIER 2대학, 연구소에서 연구 목적으로 사용
- 안정적 네트워크
- 고사양
- 맞춤형
직접 계약을 통해 제공하는 전용 서버 GPU
- TIER 2스타트업에서 AI 모델 개발 진행
- 안정적 네트워크
- 고사양
- 맞춤형
직접 계약을 통해 제공하는 전용 서버 GPU
- TIER 3개인 개발자 mining을 위한 자원
- 저렴한
- 다양한
- 탄력적
경제적인 가격으로 사용하는 개인 / PC방 GPU
- GPU 모델
- 0종 +
- 시간당 가격
- 0원~
- 월 사용 비용
- 0원~
- RTX 5000 Series
- RTX 4000 Series
- RTX 3000 Series
- RTX 2000 Series
- RTX A Series
- RTX ADA Series
- etc
실시간 GPU 사용 분석 데이터에 기반하여
합리적인 비용 체계를 구축하고
분석 데이터를 투명하게 공개합니다.
2025/06/08 15:30:27 routes.go : 1259 : INFO server config env=”map[CUDA_VISIBLE_DEVICES:
GPU_DEVICE_ORDINAL: HIP_VISIBLE_DEVICES: HSA_OVERRIDE_GFX_VERSION:HTTPS_PROXYL
HTTP_PROXY: NO_PROXY: OLLAMA_DEBUG:false OLLAMA_FLASH_ATTENTION:false
OLLAMA_GPU_OVERHEAD:0 OlLAMA_HOST:http://0.0.0.0:11434 OLLAMA_INTEL_GPU:false
OLLAMA_KEEP_ALIVE:5m0s OLLAMA_KV_CACHE_TYPE: OLLAMA_LLM_LIBRARY:
OLLAMA_LOAD_TIMEOUT:5m0s OLLAMA_MAX_LOADED_MODELS:0 OLLAMA_MAX_QUEUE:512
OLLAMA_MODELS:/root/.ollama/models OLLAMA_MULTIUSER_CACHE:false OLLAMA_NOHISTORY:false
OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:0 OLLAMA_ORIGINS:[http://localhost
http://localhost http://localhost:* https://localhost:* http:127.0.0.1 https://127.0.0.1
http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:*
http://0.0.0.0* app://* file://* tauri://* vscode-webview://*] OLLAMA_SCHED_SPREAD:false
ROCR_VISIBLE_DEVICES: http_proxy:https_proxy: no_proxy:]”
time=2025-06-18T15:30:27.553Z level=INFO source=images.go:757 msg=”total blobs: 5”
time=2025-06-18T15:30:27.553Z level=INFO source=images.go:757 msg=”total unused blobs removed: 0”
[GIN-debug] [WARNING] Creating an Engine instance with the Logger and Recovery middleware alreay attached.
[GIN-debug] [WARNING] Running in “debug” mode. Switch to “release” mode in production.
- using env: export GIN_MODE=release
2025/06/08 15:30:27 routes.go : 1259 : INFO server config env=”map[CUDA_VISIBLE_DEVICES:
GPU_DEVICE_ORDINAL: HIP_VISIBLE_DEVICES: HSA_OVERRIDE_GFX_VERSION:HTTPS_PROXYL
HTTP_PROXY: NO_PROXY: OLLAMA_DEBUG:false OLLAMA_FLASH_ATTENTION:false
OLLAMA_GPU_OVERHEAD:0 OlLAMA_HOST:http://0.0.0.0:11434 OLLAMA_INTEL_GPU:false
OLLAMA_KEEP_ALIVE:5m0s OLLAMA_KV_CACHE_TYPE: OLLAMA_LLM_LIBRARY:
OLLAMA_LOAD_TIMEOUT:5m0s OLLAMA_MAX_LOADED_MODELS:0 OLLAMA_MAX_QUEUE:512
OLLAMA_MODELS:/root/.ollama/models OLLAMA_MULTIUSER_CACHE:false OLLAMA_NOHISTORY:false
OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:0 OLLAMA_ORIGINS:[http://localhost
http://localhost http://localhost:* https://localhost:* http:127.0.0.1 https://127.0.0.1
http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:*
http://0.0.0.0* app://* file://* tauri://* vscode-webview://*] OLLAMA_SCHED_SPREAD:false
ROCR_VISIBLE_DEVICES: http_proxy:https_proxy: no_proxy:]”
time=2025-06-18T15:30:27.553Z level=INFO source=images.go:757 msg=”total blobs: 5”
time=2025-06-18T15:30:27.553Z level=INFO source=images.go:757 msg=”total unused blobs removed: 0”
[GIN-debug] [WARNING] Creating an Engine instance with the Logger and Recovery middleware alreay attached.
[GIN-debug] [WARNING] Running in “debug” mode. Switch to “release” mode in production.
- using env: export GIN_MODE=release
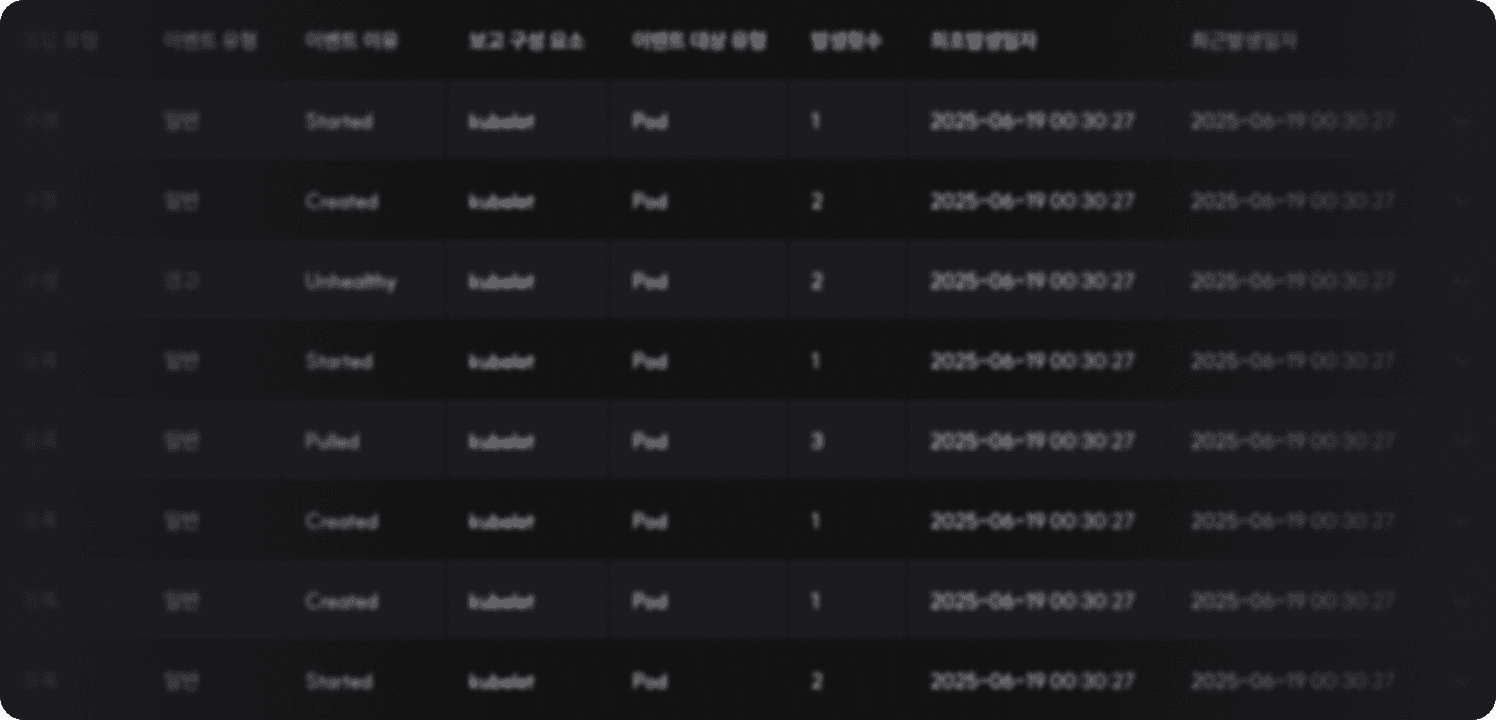
- 컨테이너 로그
워크로드 배포 후 실시간 워크로드 운영 로그 조회가 가능합니다.
 WARNINGStartup probe failed: Get "http://10.249.7.253:15021/healthz/ready": dial tcp 10.249.7.253:15021: connection refused
WARNINGStartup probe failed: Get "http://10.249.7.253:15021/healthz/ready": dial tcp 10.249.7.253:15021: connection refused- 배포 이벤트 현황
워크로드 운영 시 상태 변경 내역을 실시간으로 공유합니다.콘솔 알림을 통해서도 제공하여 연결해제나 상태 변경을 즉각 확인하고 필요한 조취를 할 수 있습니다.
- 모니터링
워크로드 실행 시 연결된 GPU의 시간별 리소스 사용량을 공개합니다.
GPU 비용 산정의 데이터를 사용자와 공유하여 신뢰할 수 있는 서비스를 제공 합니다.
필요한 GPU가 있으신가요?
상세 스펙의 GPU가 필요한 경우 문의주시면,GPU 예약 문의하기
맞춤형 GPU를 추천해드립니다.공유할 GPU가 있으신가요?
대량 공급 상담이나 GPU 공유 관련 기술지원이GPU 공급 문의하기
필요하다면 지금 문의주세요.
gcube Lab
FAQ
gcube Partners










